
Ceph 中的 Pools 和 PGs
在部署完 Ceph 集群后, Ceph 会默认建有一个存储池 Pool. Pool 能够为我们提供一些需要的功能.
Table of Contents
Ceph 中的 Pool
如果没有创建一个 Pool, Ceph 会默认有一个叫 rbd 的 Pool. Ceph 中的 Pool 可以提供以下功能:
- 弹性 (
Resilience): 可以设置允许多少OSDs错误而不丢失数据. - 位置群组 (
Placement Groups): CRUSH规则:- 快照 (
Snapshot): Ceph pool 支持对 Pool 创建快照. - 所有权 (
Owership): 可以设定一个 user 作为一个 pool 的拥有者.
Pool 的基本操作
你可以 列举(list), 建立(create), 移走(remove) pools.
列出所有 Pools
列出集群中的pools,
1 | $ ceph osd lspools |
在新部署的集群上, 只有 rbd 一个pool.
建立一个 Pool
在创建一个 pool 之前, 需要了解 pool 的 Placement Groups 和 Number of Placement Groups 的测略. 每个 osd 建议 设置 100pg, 但 pg总数 要除以副本数. 比如, 11 个 osd, size 设置为 3, 那么 pg 数应该设置为 (100*11)/3=367 ~ 400. 官方建议重写ceph配置文件里默认的 pg 数, 因为默认的不总会是最优的. 修改配置文件中的如下选项
1 | osd pool default pg num = 256 |
官方给的推荐是
- 少于 5 OSDs, pg_num 设为 128
- 5 到 10 OSDs, pg_num 设为 512
- 10 到 50 OSDs, pg_num 设为 5096
- 超过 50 OSDs, 需要自己平衡计算 pg_num
- Ceph 官方提供了一个工具 pgcalc 来计算 pg_num
同时, 可以设置默认的副本数和最小副本数:
1 | osd pool default size = 3 |
创建一个 pool,
1 | $ ceph osd pool create {pool-name} {pg-num} [{pgp-num}] [replicated] [crush-ruleset-name] [expected-num-objects] |
各个参数的意义如下:
- {pool-name}
- desc: Pool 的名字, 不能重复.
- type: string.
- required: yes.
- {pg-num}
- desc: Pool 的 Placement groups 数, 默认为 8, 基本不能满足需要, 一般要重写
- type: integer
- required: yes
- default: 8.
- {pgp_num}
- desc: 为配置目的而设的 pg 总数. 一般等于 pg 数.
- type: integer.
- required: yes. 如果没有指定, 则为默认值.
- default: 8.
- {replicated|erasure}
- desc: 标明 Pool 的类型是多副本(replicated)的以能够从损坏的 OSDs 中恢复数据, 还是 消除(erasure) 的以获得 广义的 RAID5 兼容性.
- type: string.
- require: no.
- default: replicated.
- [crush-ruleset-name]
- desc: crush ruleset 的名字. 指定的 ruleset 必须存在.
- type: string
- required: no
- default: 对于 replicated pools, 其值是由
osd pool default crush replicated ruleset设定. 对于 erasure pools, 如果
- [erasure-code-profile=profile]
- desc:
- type: string.
- required: no.
- [expected-num-objects]
- desc: xxx
- type: integer.
-required: no. - default: 0, no splitting at the pool creation time.
例如, 创建一个 名叫 test-pool, pg 和 pgp 为 128 的 Pool,
1 | $ ceph osd pool create test-pool 128 128 |
重命名一个 Pool
对一个 Pool 重命名很简单,
1 | $ ceph osd pool rename test-pool test-pool-new |
但如果有一个 user 对原 pool 配置了权限, 需要先更新 user 的权限到新的 pool, 再重命名 pool.
设置 Pool 配额
可以对一个 Pool 的 Object 个数和容量大小设置限制.
1 | ### Object |
删除一个 Pool
除一个 Pool 会同时清空该 Pool 下所有的数据, 是非常危险的操作(想想 rm -rf /). 因此在删除 Pool 时, 需要输入 Pool 名字两次, 再加上 --yes-i-really-really-mean-it
1 | $ ceph osd pool delete pool_to_delete pool_to_delete --yes-i-really-really-mean-it |
为了能删除一个 Pool, 你还必须在配置文件中设置 mon_allow_pool_delete 为 true,否则无法删除 pool.
1 | mon_allow_pool_delete = true |
更改配置文件后, 你需要重启所有 Ceph 服务.
查看 Pool 状态
1 | $ rados df |
创建删除快照
Ceph 支持对 整个 Pool 创建快照, 作用于该 Pool 下的所有对象. Ceph 中 Pool 有两种模式:
- Pool Snapshot, 建立一个 Pool时的默认模式, 也即下面要讨论的模式.
- Self Managed Snapshot, librbd 管理的 snapshot. 如果在 Pool 中创建过 rbd 对象, 该 Pool 会自动转化为这种模式.
- 注意, 这两种模式是互斥的. 若对 Pool 创建了快照, 则不能创建 rbd 对象; 若在 Pool 中创建了(过) rbd 对象, 则不能再对 Pool 做快照.
1 | ### create a snapshot |
从快照里恢复文件
1 | ### 写入文件 |
设置获取 Pool 属性
Pool 的属性可以通过如下命令语法设置
1 | $ ceph osd pool set {pool-name} {key} {value} |
例如,设置 Pool 的冗余副本数
1 | $ ceph osd pool set test-pool size 3 |
Pool 的属性可以通过如下命令语法获得,
1 | $ ceph osd pool get {pool-name} {key} {value} |
例如, 获取 Pool 的 pg_num,
1 | $ ceph osd pool get test-pool pg_num |
Pool 的属性有:
- size
- desc: Pool 中对象存储的副本数. replicated pools only.
- type: integer
- default: 3
- min_size
- desc: 可以进行读写的最小副本数. replicated pools only.
- type:
- crash_replay_interval
- desc: 允许客户端回应应答的秒数, 除了未授权的请求除外.
- type: integer
- pg_num: Pool 建立之时指定, 只能增大??
- pgp_num
- crush_ruleset
- haspspool
- desc: (取消)设置
HASHPSPOOL标志. - type: integer, 1 for setting flags, 0 for unsetting flag.
- desc: (取消)设置
- nodelete
- desc: (取消)设置
NODELETE标志. 标志一个 Pool 是否可以被删除. - type: integer. 1 for setting flag, 0 for unsetting flag
- desc: (取消)设置
- nopgchange
- desc: (取消)设置
NOPGCHANGE标志. 标志一个 Pool 是否可以更改 pg_num - type: integer. 1 for setting flag, 0 for unsetting flag.
- desc: (取消)设置
- nosizechange:
- desc: (取消)设置
NOSIZECHANGE标志. 标志一个 Pool 是否可以改变 副本数. - type: integer. 1 for setting flag, 0 for unsetting flag.
- desc: (取消)设置
- write_fadvise_dontneed
- desc: (取消)设置
WRITE_FADVISE_DONTNEED标志. - type: integer. 1 for setting flag, 0 for unsetting flag.
- desc: (取消)设置
- noscrub
- desc: (取消)设置
NOSCRUB标志. - type: integer. 1 for setting flag, 0 for unsetting flag.
- desc: (取消)设置
- nodeep-scrub
- desc: (取消)设置
NODEEP_SCRUB标志. - type: integer.
- desc: (取消)设置
- hit_set_type
- desc: 启用对 cache pools 的 hit set 追踪.
- type: string.
- value: bloom, explicit_hash, explicit_object. default is bloom.
具体的含义可参考官方文档。
Placement Groups
一个 Placement Group(PG) 将一系列的对象聚合到一个 群组里, 并将这个群组映射到一系列 OSDs 上去. 为什么要引入 GP 呢? 基于单个对象模式追踪对象的位置和元数据是非常耗费计算资源的, 一个有数以百万计对象的系统追踪位置和元数据是完全不现实的. 而 placement groups 则比较好地处理了性能和可扩展性的界限. 此外, placement groups 降低了 Ceph 必须存储和获取数据时的处理数和单个对象的元数据量.
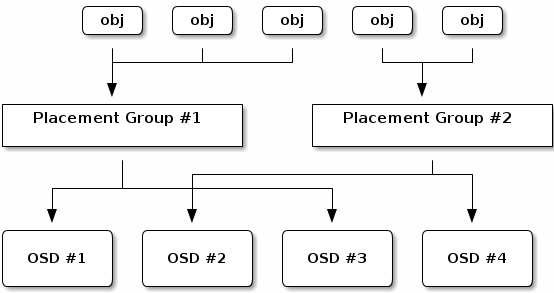 Ceph PG structure
Ceph PG structurePG 会额外消耗一部分系统资源.
- 直接地: 每一个 PG 会需要一定量的内存和CPU.
- 间接地: PGs 的总数会增加系统的 Peering 数.
增加 Pool 的 PG 数会减少集群中单个 OSD 的负载变化. 一般地, 只有一个 Pool的情况下, 可以简单地用如下公式计算 PG 数:
1 | (OSDs * 100) |
但是多个 Pools 的情况下, 你需要确保你平衡了单个 Pool 的 PG 数和 单个 OSD上的 PG数, 以找到一个合理的 PGs 总数, 能够在不加重系统负担或使 peer 过程太慢的情况下提供合理的单个 OSD 较低的变动.
设置 Pool 的 PG 数
Pool 的 PG 数必须在 Pool 建立之时就得指定.
获取 Pool 的 PG/PGP 数
1 | ### pg_num |
查看 PG 状态信息
1 | [ceph@ceph0 ~]$ ceph pg stat |
获取 集群的 PG 统计信息
1 | $ ceph pg dump [--format <format>] |
format 为 plain 和 json 两者之一.
获取卡住的 PG 的统计信息
1 | $ ceph pg dump_stuck inactive|unclean|stale [--format <format>] [-t|--threshold <seconds>] |
处于 STUCK 状态的 pg 有三种 特定的状态:
- inactive: PGs 无法处理读写请求, 它们在等待拥有最新数据的 OSD 启动并加入进来.
- unclean: PGs 中有对象存储的副本数没有达到期望的副本数.
- stale: PGs 处于不可知状态. 存储它们的 OSDs 已经有一段时间没有向 Cluster 的 Monitors 报告状态了.
format 有 plain 和 json两种格式. threshold 定义了 pg 进入 stuck 状态的最小秒数.
获取一个 PG 的 映射
获取指定 PG 的 映射(map):
1 | $ ceph pg map {pg-id} |
如
1 | [ceph@ceph0 ~]$ ceph pg map 1.17c |
Ceph 会返回 PG map, PG id, 和 对应的OSD 的状态.
获取一个 PG 的统计信息
1 | $ ceph pg {pg-id} query |
如
1 | [ceph@ceph0 ~]$ ceph pg 1.17c query |
擦洗一个 PG
如果你觉得 一个 PG 不太干净, 可以对这个 PG 进行擦洗:
1 | $ ceph pg scrub {pg-id} |
Ceph 会检查主副节点, 生成一个该 Pool 内的所有对象的日志,相互比较以确保没有文件遗失或不匹配, 并且对象内容一致. 假定所有副本都匹配, 最后的语法扫描会确保所有与快照相关的元数据也一致. 错误会通过 log 记录下来.
恢复对象 LOST 状态
如果 集群已经失去了一个或多个 对象, 你决定放弃这个对象, 你应该标记这个对象为 lost. 如果所有可能的位置都已经查寻过,仍没有找到, 你也许应该放弃这些丢失的对象.
现在只有一个选项受支持 - revert, 这会将一个对象回滚到之前的版本,若新的对象的话则直接舍弃. 要将一个unfound 对象标记为 lost, 可以用下面的命令:
1 | $ ceph pg {pg-id} mark_unfound_lost revert |
使用须谨慎. 这会让应用搞不清对象是否还在.


